
IMDb category generalization
Predicting movie themes based on their metadata. Generalizing categories for better classification.

TV Show Script Generation
Generating TV show scripts using natural language processing. Using parsing methods to create unique dialogue.
Diabetes Data Analysis
Studying the effects of income class on diabetes. Full data analysis on income class, country wealth, and more.

Discord Producer Tags
A Discord bot that gives producer tags and plays them whenever you join a voice channel.

Deepspeech Keyword Spotting
Creating a speech recognition model that can identify keywords based on their MFCC's
Results
The CNN achieved a validation accuracy of ~84% after 10 epochs, with a training accuracy of 90%, indicating a reasonable fit without severe overfitting. The precision and recall scores, which both average at 0.85 respectively, suggest that the model performs consistently across most keywords, though certain classes (such as “go” and “down”) show lower recall.
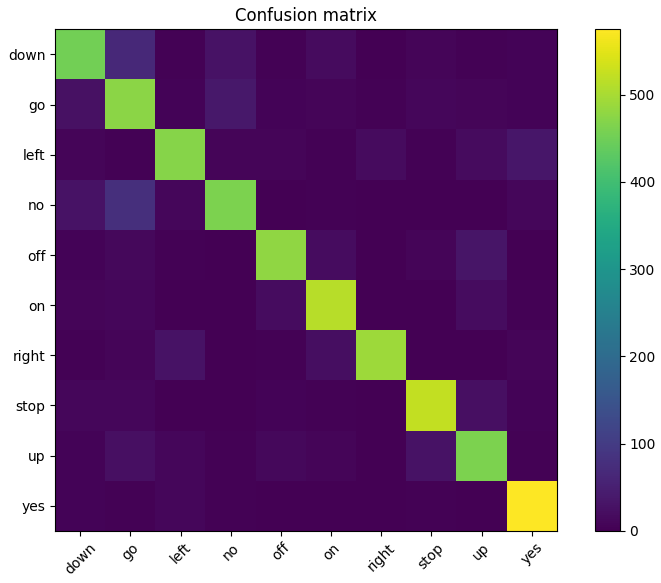
The confusion matrix reveals that most misclassifications occur between acoustically similar words (e.g., "no", "go" and "down", or "up" and "off"), which is expected in short speech segments.

CV Website (this website)
A website that displays my skills, experience, and some of my career projects.
